Lec 07-1 Learning Rate, Overfitting and Regularization
1. Determining Learning Rate
1) Try Several learning Rates ( start with 0.01 )
2) Observe the cost function
3) Check it goes down in a reasonable rate
- 너무 크면 divergence , 너무 작은면 늦게 수렴
2. Data(X) Preprocessing for gradient descent
1) RAW data가 편중되어 있을 경우, 특정 변수의 민감도가 높거나 낮아질 수 있음.
2) Normalization

3) Standardization

X_std[:,0] = (X[:0] - X[:,0].mean()) / X[:,0].std()
2. Regularization
1) OverFitting
- Our model is very good with training data set (with memorization)
- Not good at test dataset or in real use

2) Solutions for overfitting
- More Training data
- Reduce the number of features
- Regularization
3) Regularization
- Let's not have too big numbers in the weight

( Loss함수에 Weight크기를 포함하도록 함으로써 해당 값도 최소화하는 경우를 찾고자 함)
- with Tensorflow
l2reg = 0.001 * tf.reduce_sum(tf.square(W))
Lec 07-2: Training/Testing Data Set
1. Data set

2. Online Learning
1) 데이터 셋을 여러 단위로 분리해서 예측 진행
2) 이전 단계에서 예측돼었던 내용이 새로운 데이터 셋 예측에서도 동일한 영향을 주여야 함
3. M NIST Data set
Lab 07-1: training/test dataset, learning rate, normalization
1. Test Dataset & Learning Rate
0) Test Data
# Evaluation our model using this test dataset
x_test = [[2, 1, 1],
[3, 1, 2],
[3, 3, 4]]
y_test = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1]]
1) optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-10).minimize(cost)
TOOL Small : Local Min. No Progress
200 5.73203 [[ 0.80269569 0.67861289 -1.21728313]
[-0.3051686 -0.3032113 1.50825703]
[ 0.75722361 -0.7008909 -2.10820389]]
Prediction: [0 0 0]
Accuracy: 0.0
2) optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.5).minimize(cost)
TOOL Large : Divergen
200 nan [[ nan nan nan]
[ nan nan nan]
[ nan nan nan]]
Prediction: [0 0 0]
Accuracy: 0.0
3) optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
Proper Initial :
200 0.670909 [[-1.15377057 0.2814692 1.13632655]
[ 0.37484601 0.18958248 0.33544892]
[-0.35609847 -0.43973017 -1.256042 ]]
Prediction: [2 2 2]
Accuracy: 1.0
2. Normalized input
1) Large Value Raw Data
y = np.array([[828.659973, 833.450012, 908100, 828.349976, 831.659973],
[823.02002, 828.070007, 1828100, 821.655029, 828.070007],
[819.929993, 824.400024, 1438100, 818.97998, 824.159973],
[816, 820.958984, 1008100, 815.48999, 819.23999],
[819.359985, 823, 1188100, 818.469971, 818.97998],
[819, 823, 1198100, 816, 820.450012],
[811.700012, 815.25, 1098100, 809.780029, 813.669983],
[809.51001, 816.659973, 1398100, 804.539978, 809.559998]])
100 Cost: nan
Prediction:
[[ nan]
[ nan]
[ nan]
[ nan]
[ nan]
[ nan]
[ nan]
[ nan]]
Process finished with exit code 0
2) Normalized input
def MinMaxScaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
# noise term prevents the zero division
return numerator / (denominator + 1e-7)
...
xy = MinMaxScaler(xy)
100 Cost: 0.0136869
Prediction:
[[ 1.12295258]
[ 0.63500863]
[ 0.53340685]
[ 0.4315863 ]
[ 0.53191048]
[ 0.55868214]
[ 0.15761785]
[ 0.14425412]]
Process finished with exit code 0
Lab 07-2: Meet MNIST Dataset
1. MNIST Image
1) 28 * 28 * 1 Image (Binary Bitmap)

# MNIST data image of shape 28 * 28 = 784
X = tf.placeholder(tf.float32, [None, 784])
# 0 - 9 digits recognition = 10 classes
Y = tf.placeholder(tf.float32, [None, nb_classes])
2. Reading Data and set variables
from tensorflow.examples.tutorials.mnist import input_data
# Check out https://www.tensorflow.org/get_started/mnist/beginners for
# more information about the mnist dataset
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
nb_classes = 10
# MNIST data image of shape 28 * 28 = 784
X = tf.placeholder(tf.float32, [None, 784])
# 0 - 9 digits recognition = 10 classes
Y = tf.placeholder(tf.float32, [None, nb_classes])
W = tf.Variable(tf.random_normal([784, nb_classes]))
b = tf.Variable(tf.random_normal([nb_classes]))
...
batch_xs, batch_ys = mnist.train.next_batch(100)
...
print("Accuracy: ", accuracy.eval(session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
3. SoftMax
# Hypothesis (using softmax)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# Test model
is_correct = tf.equal(tf.arg_max(hypothesis, 1), tf.arg_max(Y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
4. epoch / Batch
1) 데이터가 많을 경우, 모든 데이터를 올리려면 Memory가 많이 필요하므로, Batch로 분할하여 적용
2) epoch [에폭] : 전체 데이터를 한번 모두 훈련하는 과정
3) iteration per epoch = [전체데이터 수] / [batch_size]
# parameters
training_epochs = 15
batch_size = 100
with tf.Session() as sess:
# Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
c, _ = sess.run([cost, optimizer], feed_dict={X: batch_xs, Y: batch_ys})
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
5. Result
1) 0.8951 정확도
Epoch: 0007 cost = 0.591160339
Epoch: 0008 cost = 0.563868978
Epoch: 0009 cost = 0.541745167
Epoch: 0010 cost = 0.522673571
Epoch: 0011 cost = 0.506782322
Epoch: 0012 cost = 0.492447640
Epoch: 0013 cost = 0.479955830
Epoch: 0014 cost = 0.468893666
Epoch: 0015 cost = 0.458703479
Learning finished
Accuracy: 0.8951
Label: [3]
Prediction: [5]

3을 5로 인식한 결과

7을 2로 인식하였다. 아직 89 % 정확도 이니까...
2) Learning Rate, Epoch 회수 조정으로 정확도를 더 높일 수 있다.
Learning Rate = 0.4 , Epoch = 100시 92.25%
Epoch: 0098 cost = 0.243552753
Epoch: 0099 cost = 0.243438786
Epoch: 0100 cost = 0.243145558
Learning finished
Accuracy: 0.9225
Label: [5]
Prediction: [5]

































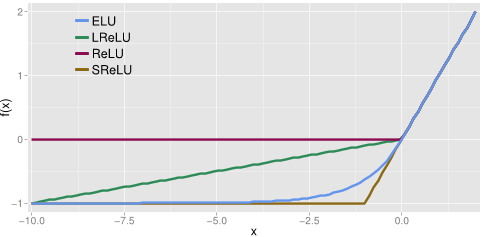

























 : 아주 큰수 ,아주 작은 수 적용시에도 선형적 가중치가 적용되어 오차 증가
: 아주 큰수 ,아주 작은 수 적용시에도 선형적 가중치가 적용되어 오차 증가

























