Lec 10-1 More than Sigmoid : ReLU
1. Vanish Gradient

Depth가 2~3일 경우에는 잘 해결되었던 문제가, Depth 가 깊어질 수록 문제해결이 어려워짐.
원인중 하나는 sigmoid함수 적용에 있는데, 아주 크거자 작은 값도 무조건 0~1 사이의 값을 보여지다 보니 그 값의 영향력이 작아지고 이로 인해 정확한 계산이 어려워 진다.
2. Geoffrey Hinton's Summary
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow.
- We initialized the weights in a stupid way.
- We used the wrong type of non-linearity.
3. ReLU

in Tensorflow
L1 = tf.sigmoid(tf.matmul(X, W1) + b1)
L1 = tf.nn.relu(tf.matmul(X, W1) + b1)
적용 예
중간 계산 과정은 모두 ReLU를 사용하고, 마지막에는 Sigmoid를 사용한다.

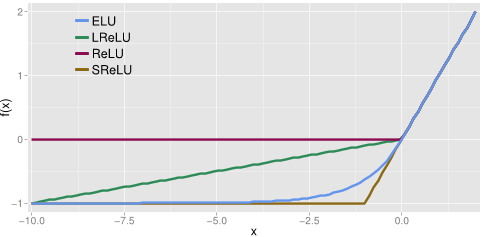
4. Activation Functions

1) Sigmoid : 0~1 사이
2) tanh : -1 ~1 사이
3) ReLU : -무시, +선형
4) Leaky ReLu :-일 경우 0.1 가중치 선형, +경우 1 가중치 선형
5) max out : 선형변환의 최대값
6) ELU : - 구간 지수함수 적용 ( 최대 -1)

Lec 10-2 Weigth 초기화 잘해보자
1. Geoffrey Hinton's Summary
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow.
- We initialized the weights in a stupid way.
- We used the wrong type of non-linearity.
2. RBM
1) Restricted Boatman Machine
2) Hinton et al. (2006) "A Fast Learning Algorithm for Deep Belief Nets”
3) concept : 1 단계별 forward & backward시 값차이가 가장 적게 발생하는 weight 값을 초기값으로 사용
4) Deep Belief Network
3. Xavier/He initialization
1) Xavier initialization:
X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in International conference on artificial intelligence and statistics, 2010
2) He’s initialization:
K. He, X. Zhang, S. Ren, and J. Sun, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,” 2015
3) Makes sure the weights are ‘just right’, not too small, not too big
4) Using number of input (fan_in) and output (fan_out)
5) application
def xavier_init(n_inputs, n_outputs, uniform=True):
"""Set the parameter initialization using the method described.
This method is designed to keep the scale of the gradients roughly the same
in all layers.
Xavier Glorot and Yoshua Bengio (2010):
Understanding the difficulty of training deep feedforward neural
networks. International conference on artificial intelligence and
statistics.
Args:
n_inputs: The number of input nodes into each output.
n_outputs: The number of output nodes for each input.
uniform: If true use a uniform distribution, otherwise use a normal.
Returns:
An initializer.
"""
if uniform:
# 6 was used in the paper.
init_range = math.sqrt(6.0 / (n_inputs + n_outputs))
return tf.random_uniform_initializer(-init_range, init_range)
else:
# 3 gives us approximately the same limits as above since this repicks
# values greater than 2 standard deviations from the mean.
stddev = math.sqrt(3.0 / (n_inputs + n_outputs))
return tf.truncated_normal_initializer(stddev=stddev)Lec 10-3 Dropout과 앙상블
1. Solutions for overfitting
1) More training data
2) Reduce the number of features
3) Regularization
2. Regularization
1) Let's not have too big numbers in the weight

2) Dropout
- A Simple Way to Prevent Neural Networks from Overfitting [Srivastava et al. 2014]

- randomly set some neurons to zero in the forward pass

3. Ensenble

Lec 10-4 레고처럼 네트워크 모듈을 마음껏 쌓아 보자

'교육&학습 > Deep Learning' 카테고리의 다른 글
| [학습] 모두를 위한 딥러닝 #10 Lec 11. Lab 11 Convolution Neural Net (0) | 2017.12.25 |
|---|---|
| [학습] 모두를 위한 딥러닝 #9 Lab 10. NN, ReLu, Xavier, Dropout and Adam (0) | 2017.12.19 |
| [학습] 모두를 위한 딥러닝 #7 Lec 09-1, 09-x, 09-2, Lab 09-1,09-2 (0) | 2017.12.11 |
| [학습] 모두를 위한 딥러닝 #6 Lec 08-1, 08-2, Lab 08 (0) | 2017.12.10 |
| [학습] 모두를 위한 딥러닝 #5 Lec 07-1, 07-2, Lab 07-01, 07-02 (0) | 2017.12.10 |




