Lec 08-1 딥러닝의 기본 개념: 시작과 XOR 문제
1. Activation Functions
사람의 신경을 연구하여 유사 구조로 만듦

2. XOR Problem :
1) 선형적 논리구조로는 풀지 못함.

2) Perceptrons (1969 ) by Marvin Minsky, founder of the MIT AI Lab
3) Backpropagation (1974, 1982 by Paul Werbos, 1986 by Hinton)

3. Convolutional Neural Networks
1) 고양이 뇌 실험
- 뇌가 이미지를 판단할 때 전체를 사용하는 것이 아니라 그림의 형태에 따라 일부의 뉴런만 사용한다.

2) 부분만 사용하여 연산한 후 나중에 합치는 방식 : LeCun

4. Big Problem
1) Backpropagation just did not work well for normal neural nets with many
2) Other rising machine learning algorithms: SVM, RandomForest, etc.
3) 1995 “Comparison of Learning Algorithms For Handwritten Digit Recognition” by LeCun et al.
found that this new approach worked better
Lec 08-2 딥러닝의 기본 개념 2: back-propagation 과 2006/2007 '딥'의 출현
1. Breakthrough : in 2006 and 2007 by Hinton and Bengio
1) Neural networks with many layers really could be trained well,
if the weights are initialized in a clever way rather than randomly.
2) Deep machine learning methods are more efficient for difficult problems than shallow methods.
3) Rebranding to Deep Nets, Deep Learning
2. ImageNet Classification (2012 ) : 26.2% -> 15.3 %

1) 2015년 standford 연구생이 코딩으로 개발한 건보다, CNN을 이용해서 개발한 모델이 정확하게 예측함
Lab 08 Tensor Manipulation
1. Array
1) Simple Array [1D]
t = np.array([0., 1., 2., 3., 4., 5., 6.])
pp.pprint(t)
print(t.ndim) # rank
print(t.shape) # shape
print(t[0], t[1], t[-1])
print(t[2:5], t[4:-1])
print(t[:2], t[3:])
array([ 0., 1., 2., 3., 4., 5., 6.])
1 -> 김성훈 교수님 예제 잘못되어 있음
(7,)
0.0 1.0 6.0
[ 2. 3. 4.] [ 4. 5.]
[ 0. 1.] [ 3. 4. 5. 6.]
2) 2D Array
t = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.], [10., 11., 12.]])
pp.pprint(t)
print(t.ndim) # rank
print(t.shape) # shape
array([[ 1., 2., 3.],
[ 4., 5., 6.],
[ 7., 8., 9.],
[ 10., 11., 12.]])
2
(4, 3)
3) Shape, Rank, Axis
Shape : 배열의 크기 - 가장 안쪽에서 뒤에서 부터 표시
Rank : 배열의 차원
Axis : 배열 요소의 순서 ( X :0 , Y : 1, Z : 3)
4) MatMul Vs multiply
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
tf.matmul(matrix1, matrix2).eval()
(matrix1*matrix2).eval()
[[ 12.]]
[[ 6. 6.]
[ 6. 6.]]
5) Watch Out Broadcast
2. Function
1) Reduce mean
tf.reduce_mean([1, 2], axis=0).eval()
x = [[1., 2.],
[3., 4.]]
tf.reduce_mean(x).eval()
tf.reduce_mean(x, axis=0).eval()
tf.reduce_mean(x, axis=1).eval()
tf.reduce_mean(x, axis=-1).eval()
1
2.5
[ 2. 3.]
[ 1.5 3.5]
[ 1.5 3.5]
2) Reduce sum
x = [[1., 2.],
[3., 4.]]
tf.reduce_sum(x).eval()
tf.reduce_sum(x, axis=0).eval()
tf.reduce_sum(x, axis=-1).eval()
tf.reduce_mean(tf.reduce_sum(x, axis=-1)).eval()
10.0
[ 4. 6.]
[ 3. 7.]
5.0
3) Argmax : 가장 큰 값의 위치가 어디냐?
x = [[0, 1, 2],
[2, 1, 0]]
tf.argmax(x, axis=0).eval()
tf.argmax(x, axis=1).eval()
tf.argmax(x, axis=-1).eval()
[1 0 0]
[2 0]
[2 0]
4) Reshape, squeeze, expand
t = np.array([[[0, 1, 2],
[3, 4, 5]],
[[6, 7, 8],
[9, 10, 11]]])
t.shape
tf.reshape(t, shape=[-1, 3]).eval()
tf.reshape(t, shape=[-1, 1, 3]).eval()
tf.squeeze([[0], [1], [2]]).eval()
tf.expand_dims([0, 1, 2], 1).eval()
(2, 2, 3)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[[ 0 1 2]]
[[ 3 4 5]]
[[ 6 7 8]]
[[ 9 10 11]]]
[0 1 2]
[[0]
[1]
[2]]
5) Onehot :
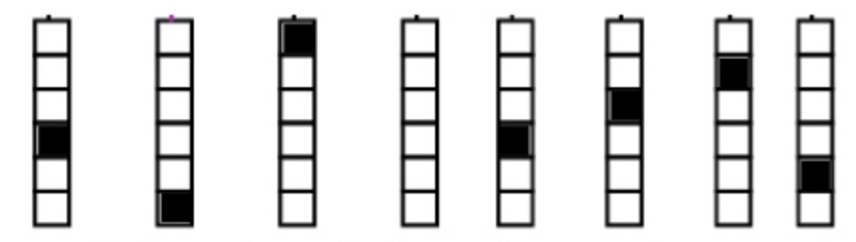
tf.one_hot([[0], [1], [2], [0]], depth=3).eval()
t = tf.one_hot([[0], [1], [2], [0]], depth=3)
tf.reshape(t, shape=[-1, 3]).eval()
[[[ 1. 0. 0.]]
[[ 0. 1. 0.]]
[[ 0. 0. 1.]]
[[ 1. 0. 0.]]]
[[ 1. 0. 0.]
[ 0. 1. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]]
6) Cast / Stack /ones-zeros / zip
tf.cast([1.8, 2.2, 3.3, 4.9], tf.int32).eval()
tf.cast([True, False, 1 == 1, 0 == 1], tf.int32).eval()
#Stack
x = [1, 4]
y = [2, 5]
z = [3, 6]
# Pack along first dim.
tf.stack([x, y, z]).eval()
tf.stack([x, y, z], axis=1).eval()
x = [[0, 1, 2],
[2, 1, 0]]
tf.ones_like(x).eval()
tf.zeros_like(x).eval()
#Zip
for x, y in zip([1, 2, 3], [4, 5, 6]):
print(x, y)
for x, y, z in zip([1, 2, 3], [4, 5, 6], [7, 8, 9]):
print(x, y, z)[1 0 0]
===cast
[1 2 3 4]
[1 0 1 0]
===stack
[[1 4]
[2 5]
[3 6]]
[[1 2 3]
[4 5 6]]
===ones, zeros
[[1 1 1]
[1 1 1]]
[[0 0 0]
[0 0 0]]
===zip
1 4
2 5
3 6
1 4 7
2 5 8
3 6 9
'교육&학습 > Deep Learning' 카테고리의 다른 글
| [학습] 모두를 위한 딥러닝 #8 Lec 10-1, 10-2, 10-3, 10-4 (0) | 2017.12.15 |
|---|---|
| [학습] 모두를 위한 딥러닝 #7 Lec 09-1, 09-x, 09-2, Lab 09-1,09-2 (0) | 2017.12.11 |
| [학습] 모두를 위한 딥러닝 #5 Lec 07-1, 07-2, Lab 07-01, 07-02 (0) | 2017.12.10 |
| [학습] 모두를 위한 딥러닝 #4 Lec 06-1, 06-2, Lab 06-01, 06-02 (0) | 2017.12.09 |
| [학습] 모두를 위한 딥러닝 #3 Lec 05-1, 05-2, Lab 05 (0) | 2017.12.07 |








 : 아주 큰수 ,아주 작은 수 적용시에도 선형적 가중치가 적용되어 오차 증가
: 아주 큰수 ,아주 작은 수 적용시에도 선형적 가중치가 적용되어 오차 증가